프로그래밍 사이트 백준 Online Judge의 시리즈 문제들인 가장 긴 증가하는 부분 수열 1~5를 풀이해보도록 하겠습니다.
이는 '최장 증가 부분 수열'이라는 이름으로도 유명한 문제이며, 동적 프로그래밍을 이용해야 하고 풀이를 위한 핵심 알고리즘에 대한 이해가 필요합니다.
11053번 : 가장 긴 증가하는 부분 수열
[C언어 백준 풀이][Silver II] 1012번 : 유기농 배추 / 11053번 : 가장 긴 증가하는 부분 수열 / 1931번 : 회
프로그래밍 문제 사이트 백준 Online Judge의 Solved.ac 기준 난이도 SIlver II에 해당하는 문제인 1012번 유기농 배추, 11053번 가장 긴 증가하는 부분 수열, 1931번 회의실 배정 문제를 풀이해보도록 하겠습
restudycafe.tistory.com
해당 문제에 대해서는 이미 풀이 및 정리를 마쳤기 때문에 제가 작성한 포스트의 링크를 첨부하니 이를 참고해주시면 되겠습니다.
그래도 풀이를 간략히 요약하자면 먼저 배열 D에 해당 번째 숫자가 최대 몇 번째에 위치할 수 있는지 기록하고, subSeq에 지금까지 탐색한 번호 내에서 선택된 최선의 수열을 저장하여 이를 활용하면 됩니다.
A 배열의 수를 하나씩 꺼내서 subSeq에 있는 번호들 중에서 들어갈 수 있는 곳을 기록하여 D[i]에 번호를 매기고, subLen에 현재까지 탐색한 번호 내에서 선택된 최선의 수열의 길이를 변수로 저장하여 탐색이 끝난 뒤 출력할 수 있도록 합니다.
위 포스트의 풀이 코드에서는 탐색 부분에서 O(N^2) 알고리즘이 사용되었습니다.
12015번 : 가장 긴 증가하는 부분 수열 2

2번 문제의 경우 조건이 강화되어 수열의 크기가 최대 100만까지 주어지게 됩니다.
이 경우 1번 문제 풀이와 같이 O(N^2) 코드를 사용할 경우 탐색 과정에서 시간 초과를 발생시키게 됩니다.
따라서 O(N log N) 시간에 해결할 수 있는 방법을 찾아야 합니다.
#include<stdio.h>
int A[1000005] = {0, }, D[1000005] = {0, 1}, subSeq[1000005] = {0, };
int main() {
int N, subLen = 1, low, mid, high;
scanf("%d", &N);
for(int i=1; i<=N; i++) scanf("%d", &A[i]);
subSeq[1] = A[1];
for(int i=2; i<=N; i++) {
low = 0, high = subLen;
while(low <= high) {
mid = (low + high)/2;
if(A[i] > subSeq[mid] && mid == subLen) {
subSeq[++subLen] = A[i];
D[i] = subLen;
break;
}
else if(A[i] > subSeq[mid] && A[i] < subSeq[mid+1]) {
subSeq[mid+1] = A[i];
D[i] = mid+1;
break;
}
else if(A[i] < subSeq[mid]) high = mid - 1;
else if(A[i] > subSeq[mid]) low = mid + 1;
else break;
}
}
printf("%d", subLen);
}
저의 경우 이진 탐색(Binary Search)을 기존 풀이 코드에 응용시켜 풀었습니다.
다만 정석적인 이진 탐색 코드의 경우 key 값과 일치하는 값을 찾는 코드인데, 여기서는 A[i]보다 크고 A[i+1]보다는 작은 i를 찾는 탐색이므로 코드를 위와 같이 수정해주어야 합니다.
그리고 적절한 값이 발견되면 subLen을 1 증가시켜주고 subSeq와 D 배열에 적절한 값을 저장시켜줍니다.
Binary Search의 시간복잡도는 O(N log N)이므로 100만개의 값을 정렬해도 시간이 초과되지 않습니다.
12738번 : 가장 긴 증가하는 부분 수열 3

3번 문제는 각 수열을 구성하는 데이터의 크기 범위가 증가한 조건을 제시합니다.
시간에 대한 문제는 없으나 데이터 범위가 달라졌기 때문에 코드를 일부 수정해주어야 합니다.
#include<stdio.h>
int A[1000005] = {0, }, D[1000005] = {0, 1}, subSeq[1000005] = {-1000000001, };
int main() {
int N, subLen = 1, low, mid, high;
scanf("%d", &N);
for(int i=1; i<=N; i++) scanf("%d", &A[i]);
subSeq[1] = A[1];
for(int i=2; i<=N; i++) {
low = 0, high = subLen;
while(low <= high) {
mid = (low + high)/2;
if(A[i] > subSeq[mid] && mid == subLen) {
subSeq[++subLen] = A[i];
D[i] = subLen;
break;
}
else if(A[i] > subSeq[mid] && A[i] < subSeq[mid+1]) {
subSeq[mid+1] = A[i];
D[i] = mid+1;
break;
}
else if(A[i] < subSeq[mid]) high = mid - 1;
else if(A[i] > subSeq[mid]) low = mid + 1;
else break;
}
}
printf("%d", subLen);
}
일반적으로 subSeq 배열은 0으로 하한을 잡고 정렬을 진행하는데, 여기서는 각 데이터의 하한이 -10억이므로 subSeq[0]의 값을 -10억보다 작은 값으로 설정해주면 됩니다.
나머지 알고리즘이나 탐색에 대한 코드는 수정하지 않아도 같은 코드로 해결할 수 있습니다.
14002번 : 가장 긴 증가하는 부분 수열 4 ~ 14003번 : 가장 긴 증가하는 부분 수열 5
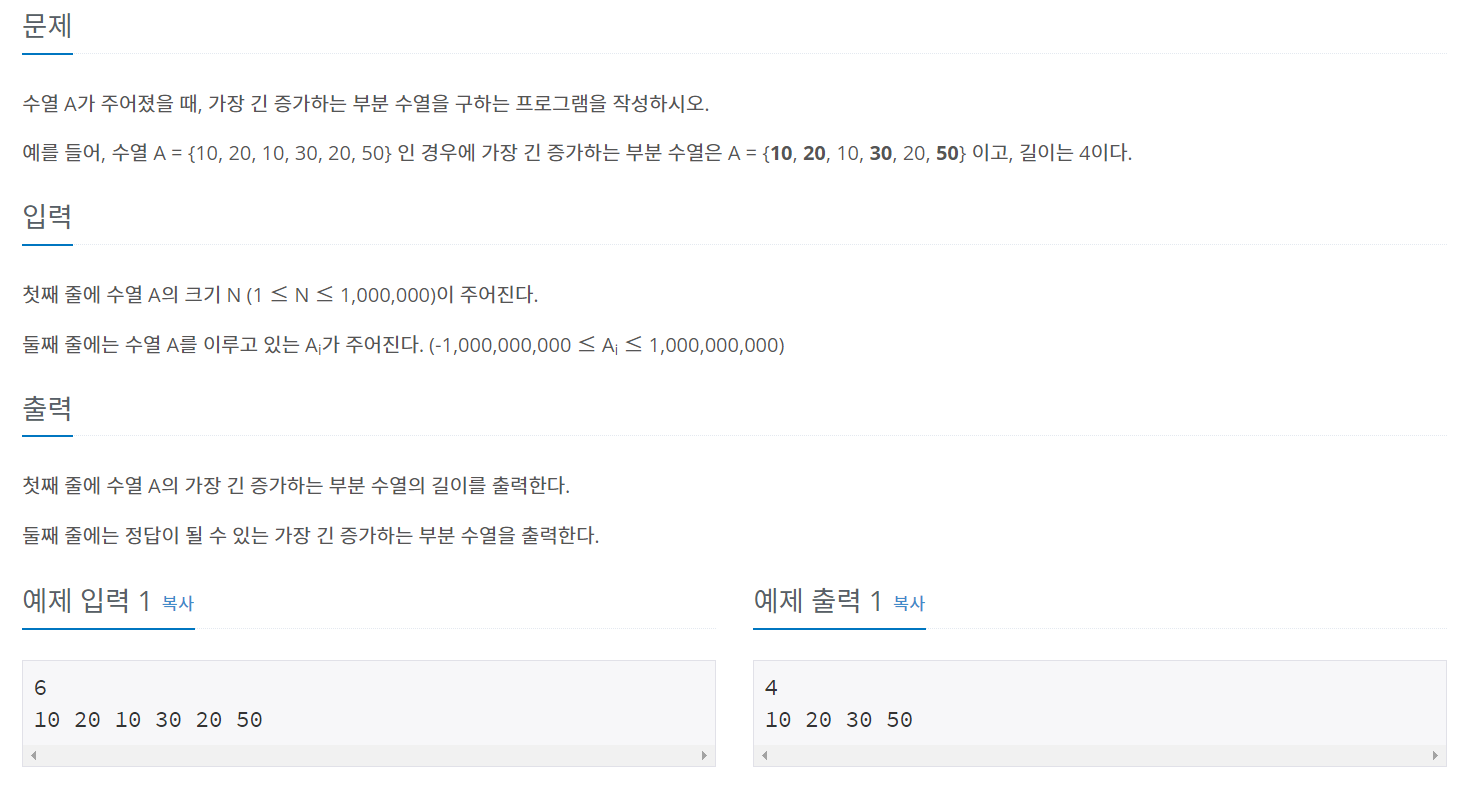
4번 문제는 가장 긴 증가하는 부분 수열의 최대 길이를 찾는 것과 동시에 예시로 들 수 있는 수열을 하나 출력해야 합니다.
다만 이를 5번 문제와 같이 배치한 이유는 5번 문제에서도 변수의 범위가 까다로워지는데 이것은 3번 문제에 대한 풀이 코드에서 이미 해결이 되었기 때문에 4번 문제만 풀면 5번 문제는 자동적으로 풀리게 되기 때문입니다.
#include<stdio.h>
int A[1000005] = {0, }, D[1000005] = {0, 1}, subSeq[1000005] = {-1000000001, }, exSeq[1000005] = {0, };
int main() {
int N, subLen = 1, low, mid, high, subLen2;
scanf("%d", &N);
for(int i=1; i<=N; i++) scanf("%d", &A[i]);
subSeq[1] = A[1];
for(int i=2; i<=N; i++) {
low = 0, high = subLen;
while(low <= high) {
mid = (low + high)/2;
if(A[i] > subSeq[mid] && mid == subLen) {
subSeq[++subLen] = A[i];
D[i] = subLen;
break;
}
else if(A[i] > subSeq[mid] && A[i] < subSeq[mid+1]) {
subSeq[mid+1] = A[i];
D[i] = mid+1;
break;
}
else if(A[i] < subSeq[mid]) high = mid - 1;
else if(A[i] > subSeq[mid]) low = mid + 1;
else break;
}
}
printf("%d\n", subLen);
subLen2 = subLen;
for(int i=N; i>0; i--) {
if(D[i] == subLen2) {
exSeq[subLen2--] = A[i];
}
}
for(int i=1; i<=subLen; i++) printf("%d ", exSeq[i]);
}
최종적인 코드는 위와 같고, 예시 Sequence를 하나 들어야 하므로 exSeq라는 새로운 배열을 하나 선언했습니다.
예시 수열을 찾는 가장 안정적인 방법은, D[i]를 모두 설정한 이후에 뒤에서부터 오면서 D[i]가 subLen 값인 것부터 subLen-1, subLen-2인 것을 하나씩 찾는 것입니다.
이 때 당연히도 exSeq의 뒷 칸부터 앞 칸 순서로 저장한 뒤 출력할 때는 차례대로 출력해주면 됩니다.
코드에 대한 부가 설명이 필요하시면, 코드를 최대한 단순하고 간략하게 작성하기 위해 노력하였으늬 코드를 직접 읽어보면서 참고하시면 될 것 같습니다.
참고로 마지막 문제의 경우 백준 및 Solved.ac에서 Platinum V의 난이도가 책정되어 있으므로 적지않은 경험치를 받으실 수 있으니 이런 시리즈 문제에 도전해보는 것을 추천드립니다.